Computer Vision with a Superpixelation Camera
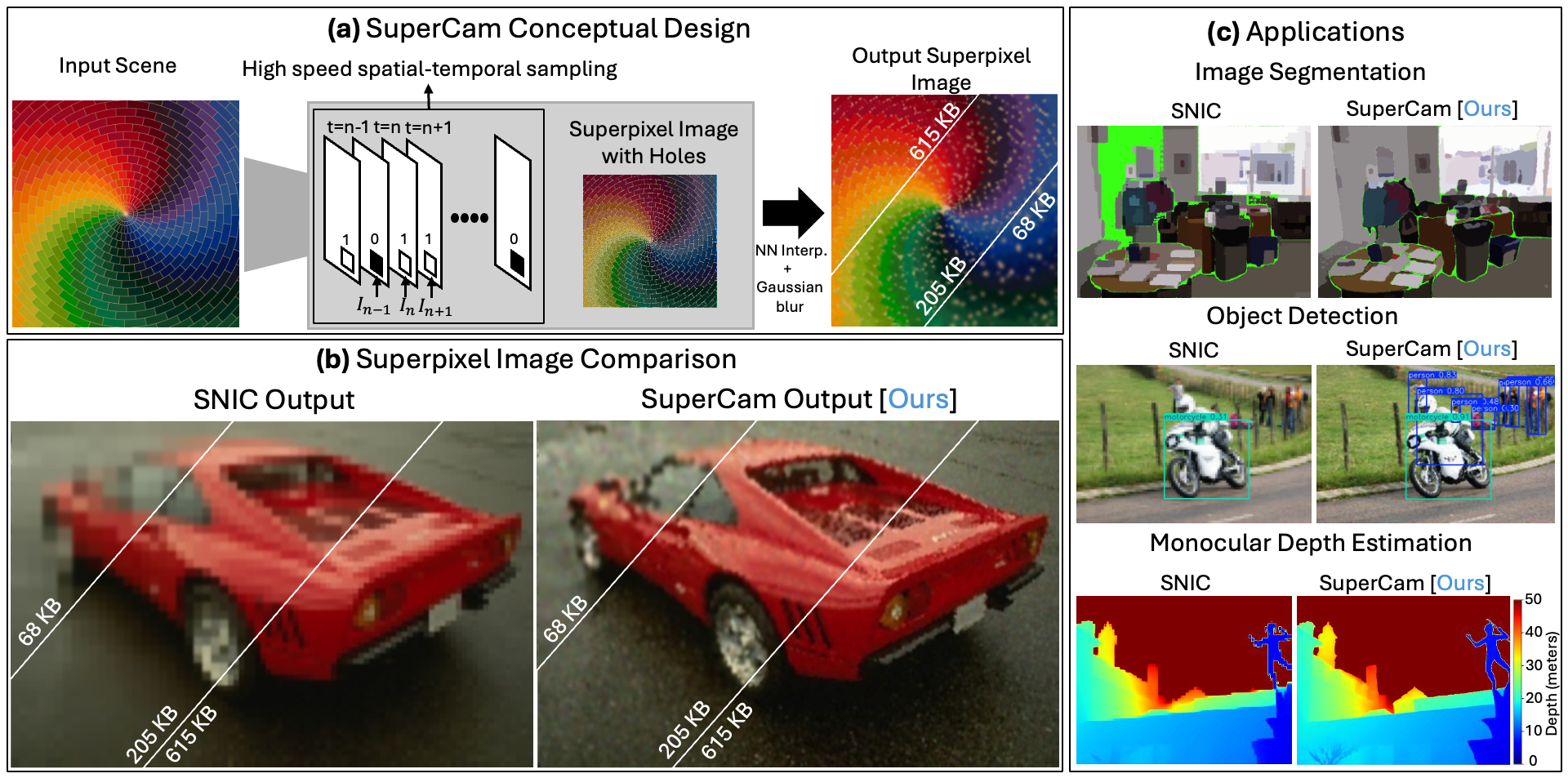
Summary of SuperCam design, output and applications:
(a) SuperCam Conceptual Design:
The proposed design, which is implemented as a passive Single Photon Avalanche Diode (SPAD) Sensor. We adaptively sample the exposed pixels to generate a sparse superpixel image.
(b) Superpixel Image Comparison:
As SuperCam generates the superpixel image from sparse data on the fly, it performs better than the conventional superpixel algorithms under resource constrained scenarios. Shown are sample images with different memory settings; 68KB, 205KB and 615KB.
(c) Applications:
Three computer vision applications comparing SuperCam with a memory-constrained implementation of SNIC Image Segmentation using SAMv2, Object Detection using YOLOv12 and Monocular Depth Estimation using DepthAnythingV2.
Abstract
Conventional cameras generate a lot of data that can be challenging to process in resource-constrained applications. Usually, cameras generate data streams on the order of the number of pixels in the image. However, most of this captured data is redundant for many downstream computer vision algorithms. We propose a novel camera design, which we call SuperCam, that adaptively processes captured data by performing superpixel segmentation on the fly. We show that SuperCam performs better than current state-of-the-art superpixel algorithms under memory-constrained situations. We also compare how well SuperCam performs when the compressed data is used for downstream computer vision tasks. Our results demonstrate that the proposed design provides superior output for image segmentation, object detection, and monocular depth estimation in situations where the available memory on the camera is limited. We posit that superpixel segmentation will play a crucial role as more computer vision inference models are deployed in edge devices. SuperCam would allow computer vision engineers to design more efficient systems for these applications.
Superpixel Image Comparison
We compare memory restricted SNIC (we artificially reduce the image resolution to fit the algorithm into the various memory budgets shown) to SuperCam images using the same amount of memory. Below are results for three chosen memory budgets 68KB, 205KB and 615KB.
 Restricted SNIC - 68KB
Restricted SNIC - 68KB
 SuperCam - 68KB
SuperCam - 68KB
 Restricted SNIC - 205KB
Restricted SNIC - 205KB
 SuperCam - 205KB
SuperCam - 205KB
 Restricted SNIC - 615KB
Restricted SNIC - 615KB
 SuperCam - 615KB
SuperCam - 615KB
 Restricted SNIC - 68KB
Restricted SNIC - 68KB
 SuperCam - 68KB
SuperCam - 68KB
 Restricted SNIC - 205KB
Restricted SNIC - 205KB
 SuperCam - 205KB
SuperCam - 205KB
 Restricted SNIC - 615KB
Restricted SNIC - 615KB
 SuperCam - 615KB
SuperCam - 615KB
 Restricted SNIC - 68KB
Restricted SNIC - 68KB
 SuperCam - 68KB
SuperCam - 68KB
 Restricted SNIC - 205KB
Restricted SNIC - 205KB
 SuperCam - 205KB
SuperCam - 205KB
 Restricted SNIC - 615KB
Restricted SNIC - 615KB
 SuperCam - 615KB
SuperCam - 615KB
 Restricted SNIC - 68KB
Restricted SNIC - 68KB
 SuperCam - 68KB
SuperCam - 68KB
 Restricted SNIC - 205KB
Restricted SNIC - 205KB
 SuperCam - 205KB
SuperCam - 205KB
 Restricted SNIC - 615KB
Restricted SNIC - 615KB
 SuperCam - 615KB
SuperCam - 615KB
 Restricted SNIC - 68KB
Restricted SNIC - 68KB
 SuperCam - 68KB
SuperCam - 68KB
 Restricted SNIC - 205KB
Restricted SNIC - 205KB
 SuperCam - 205KB
SuperCam - 205KB
 Restricted SNIC - 615KB
Restricted SNIC - 615KB
 SuperCam - 615KB
SuperCam - 615KB
Computer Vision Tasks
We show the performance of SuperCam on three downstream tasks: Image Segmentation, Object Detection and Monocular Depth Estimation.
Image Segmentation
Comparison of the performance of Segment Anything Model v2 on the BSD500 dataset
 Restricted SNIC - 68KB
Restricted SNIC - 68KB
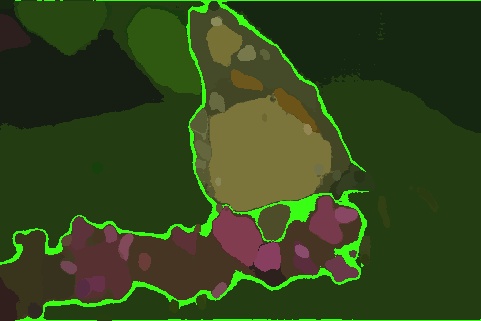 SuperCam - 68KB
SuperCam - 68KB
 Restricted SNIC - 205KB
Restricted SNIC - 205KB
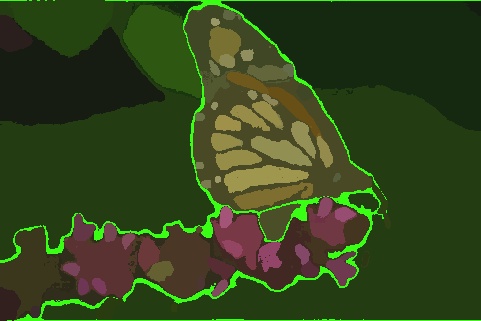 SuperCam - 205KB
SuperCam - 205KB
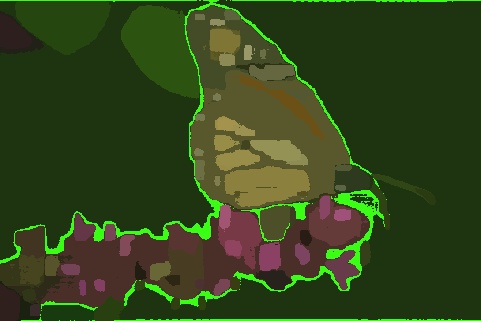 Restricted SNIC - 615KB
Restricted SNIC - 615KB
 SuperCam - 615KB
SuperCam - 615KB
 Restricted SNIC - 68KB
Restricted SNIC - 68KB
 SuperCam - 68KB
SuperCam - 68KB
 Restricted SNIC - 205KB
Restricted SNIC - 205KB
 SuperCam - 205KB
SuperCam - 205KB
 Restricted SNIC - 615KB
Restricted SNIC - 615KB
 SuperCam - 615KB
SuperCam - 615KB
Object Detection
Comparison of the performance of YOLOv12 model on the COCO dataset
 Restricted SNIC - 479KB
Restricted SNIC - 479KB
 SuperCam - 479KB
SuperCam - 479KB
 Restricted SNIC - 684KB
Restricted SNIC - 684KB
 SuperCam - 684KB
SuperCam - 684KB
 Restricted SNIC - 1025KB
Restricted SNIC - 1025KB
 SuperCam - 1025KB
SuperCam - 1025KB
 Restricted SNIC - 479KB
Restricted SNIC - 479KB
 SuperCam - 479KB
SuperCam - 479KB
 Restricted SNIC - 684KB
Restricted SNIC - 684KB
 SuperCam - 684KB
SuperCam - 684KB
 Restricted SNIC - 1025KB
Restricted SNIC - 1025KB
 SuperCam - 1025KB
SuperCam - 1025KB
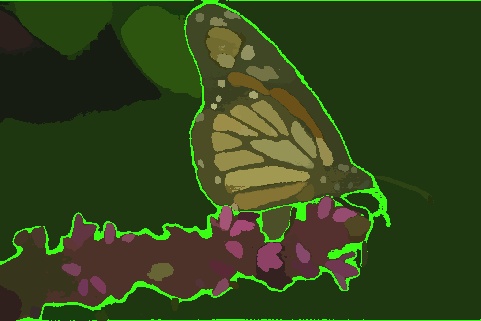
Monocular Depth Estimation
Comparison of the performance of Depth Anything v2 model on the DIODE dataset
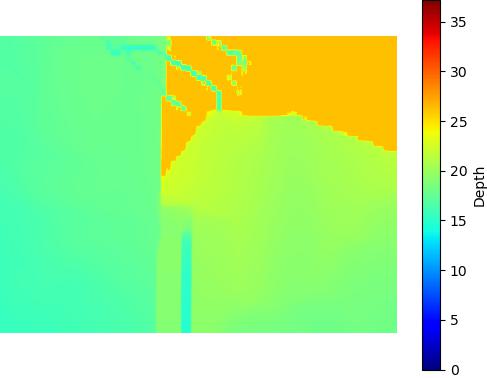 Restricted SNIC - 410KB
Restricted SNIC - 410KB
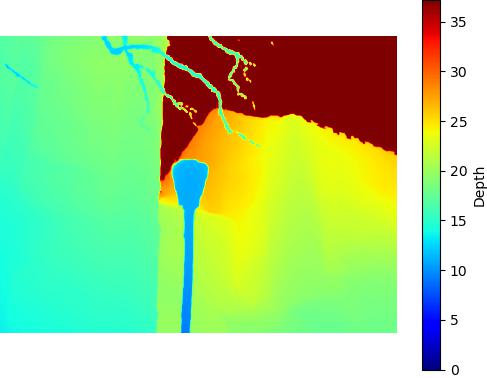 SuperCam - 410KB
SuperCam - 410KB
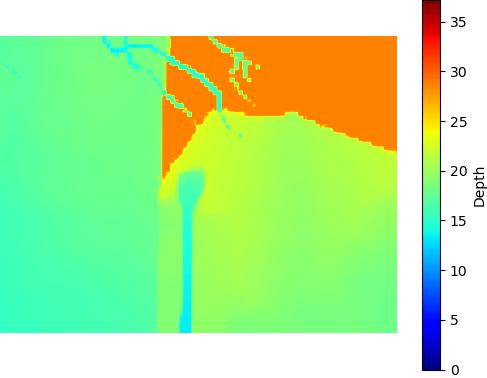 Restricted SNIC - 547KB
Restricted SNIC - 547KB
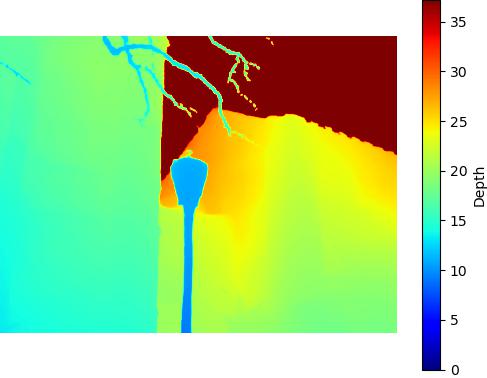 SuperCam - 547KB
SuperCam - 547KB
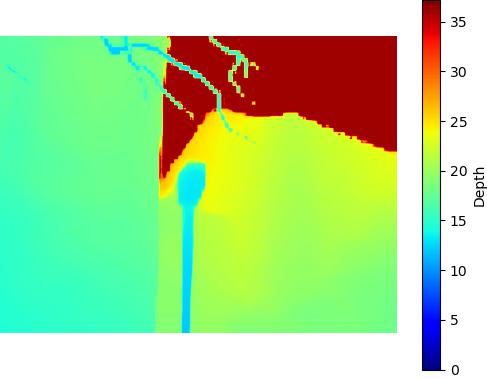 Restricted SNIC - 684KB
Restricted SNIC - 684KB
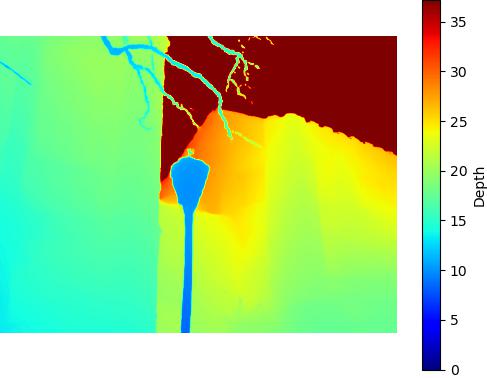 SuperCam - 684KB
SuperCam - 684KB
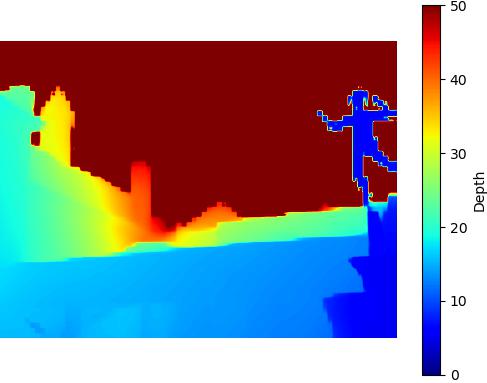 Restricted SNIC - 410KB
Restricted SNIC - 410KB
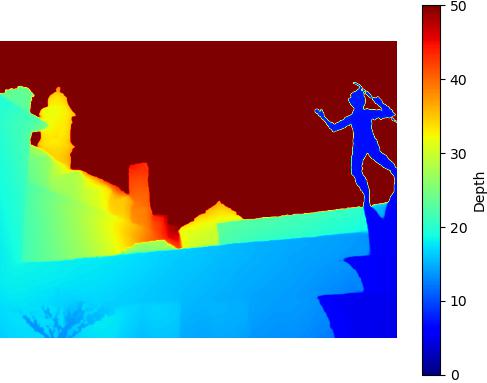 SuperCam - 410KB
SuperCam - 410KB
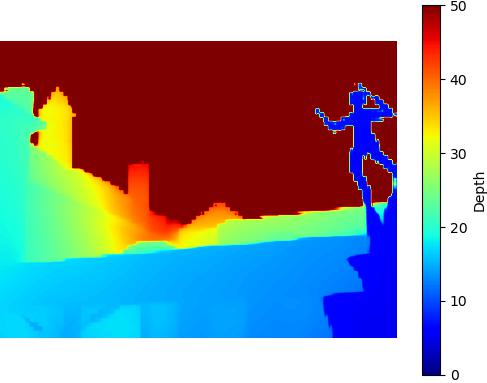 Restricted SNIC - 547KB
Restricted SNIC - 547KB
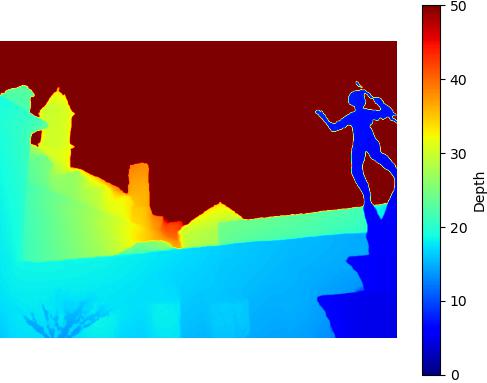 SuperCam - 547KB
SuperCam - 547KB
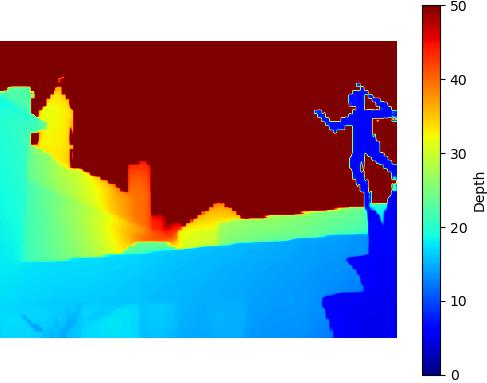 Restricted SNIC - 684KB
Restricted SNIC - 684KB
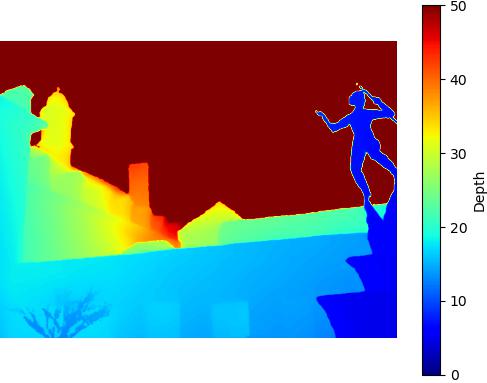 SuperCam - 684KB
SuperCam - 684KB
Hardware Emulation Results
We show hardware emulation results of our proposed SuperCam design on downstream computer vision tasks; namely image segmentation performance of Segment Anything Model v2, object detection performance of YOLOv12 model and monocular depth estimation performance of Depth Anything v2 model.
Hardware Emulation results of SuperCam: We show hardware emulation results of SuperCam and compare it with memory restricted SNIC using the same amount of memory for different computer vision tasks. We use this open source dataset which was captured using the SwissSPAD2 sensor.
Frequently Asked Questions
Computational Efficiency: Processing an image as a few hundred superpixels instead of millions of individual pixels drastically reduces the "search space" for algorithms like object tracking or depth estimation.
Feature Preservation: Unlike standard downsampling (which blurs edges), superpixels are boundary-aware. They conform to the shapes of objects in a scene, preserving high-frequency details like edges and contours that are often lost in low-resolution grids.
Reduced Redundancy: In most natural scenes, neighboring pixels carry nearly identical information (e.g., a blue sky or a white wall). Superpixels represent these uniform areas as a single unit, allowing the camera or processor to focus its "attention" only where the scene actually changes.
BibTeX
@article{cvpr2026supercam,
title={Computer Vision with a Superpixelation Camera},
author={Mahalingam, Sasidharan and Brown, Rachel and Ingle, Atul},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}